随着信息时代的到来,网站被认为是获取信息的主要途径之一。但是,手动获取网站上的信息是非常繁琐的,因此出现了自动抓取网页的方式——网络爬虫。这篇文章将介绍如何使用PHP和Selenium搭建一个高效的网络爬虫来自动收集信息。 安装PHP和SeleniumSelenium是一个Web自动化测试工具,它模拟用户在Web页面上的操作。Selenium可以与多种语言进行交互,其中包括PHP。 在PHP中集成Selenium安装PHP的 Selenium库。可以通过Composer来安装它:composer require facebook/webdriver定义你的Web驱动程序这里使用的是Chrome浏览器,当然Selenium支持多种浏览器。可以将下面的代码保存为一个单独的文件: use FacebookWebDriverRemoteDesiredCapabilities;
模拟用户的操作例如,访问一个网站: $driver->get('http://news.baidu.com');这将打开百度新闻并获取所有的新闻链接: $news_links = $driver->findElements(WebDriverBy::cssSelector('.c-title a'));
现在你获得了所有的新闻链接,你可以遍历它们依次爬取每个链接的内容: foreach ($links as $link) {
以上就是用PHP和Selenium搭建高效的网络爬虫的基础。当然,如果需要进一步优化,可以结合多个工具和技术来使用,例如使用多线程来提高效率,使用字体反混淆来解决有些网站将字体反混淆的问题, etc. 爬虫的世界千奇百怪,愿你能发现最适合自己的方法和工具! 上一篇:震后余生:九年后,我还是被困住了 下一篇:“浦发硅谷银行” 成历史 |
 微信公众平台持续治理“假冒仿冒”行为16130 人气#新媒体课堂
微信公众平台持续治理“假冒仿冒”行为16130 人气#新媒体课堂 公众号案例 | 鲲鹏产业源头创新中心微信公28356 人气#新媒体课堂
公众号案例 | 鲲鹏产业源头创新中心微信公28356 人气#新媒体课堂 萌芽加速 adminCDN 上线,由文派开源提供的17976 人气#站长圈
萌芽加速 adminCDN 上线,由文派开源提供的17976 人气#站长圈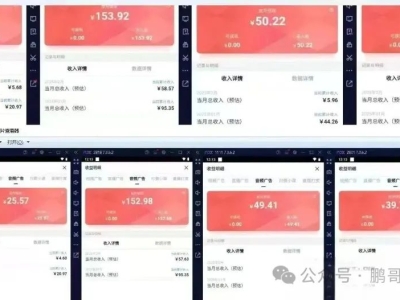 搜狐音频挂机项目揭秘:月入八千+的红利期操28847 人气#站长资讯
搜狐音频挂机项目揭秘:月入八千+的红利期操28847 人气#站长资讯
 /1
/1 
 AI智能体
AI智能体









