| 聊天机器人(Chatbot),又被称为对话代理(Conversational Agents)或对话系统(Dialog Systems),是当前的一个研究热点。Microsoft在聊天机器人领域下了巨大赌注,其他的公司,例如Facebook(M)、Apple(Siri)、Google、WeChat和Slack也不甘落后,推出了相关的产品。这股聊天机器人的新浪潮,也在一些创业公司兴起了:试图改变用户和服务之间的交互模式的产品 Operator 和 x.ai,机器人开发平台 Chatfuel,机器人开发库 Howdy’s Botkit 等。Microsoft最近也公开了他们自己的 机器人开发框架。 许多公司希望机器人能够像人类一样自然地对话,而NLP和深度学习技术则是他们寄予厚望的实现方式。但是炒作归炒作,我们必须直面的现实是,AI有些时候的表现还是和我们的期望相去甚远的。 在这个系列的blog中,我们将会介绍用于搭建聊天机器人模型的深度学习技术,让大家对于“这个领域中,什么是能做到的,什么是现阶段几乎不可能实现的”有一个大致的了解。本文仅是一个综述,实现细节将会在该系列接下来的blog中推出。 模型分类基于检索的模型 vs. 产生式模型基于检索的模型(Retrieval-Based Models)有一个预先定义的“回答集(repository)”,包含了许多回答(responses),还有一些根据输入的问句和上下文(context),以及用于挑选出合适的回答的启发式规则。这些启发式规则可能是简单的基于规则的表达式匹配,或是相对复杂的机器学习分类器的集成。基于检索的模型不会产生新的文字,它只能从预先定义的“回答集”中挑选出一个较为合适的回答。 产生式模型(Generative Models)不依赖于预先定义的回答集,它会产生一个新的回答。经典的产生式模型是基于机器翻译技术的,只不过不是将一种语言翻译成另一种语言,而是将问句“翻译”成回答(response)。 两种构建模型的方式都有其明显的优点和缺点。对于基于检索的模型,由于“回答集”是手工编写的回答,因此几乎不会有语法错误。然而,正是因为回答都是预先定义的,该模型有两个明显缺点:1)无法处理没见过的问题,因为此时数据库中没有合适的回答;2) 无法追溯上文中的实体信息,例如上文提到的人名、地名。相对来说,产生式模型就更“智能”,他们能处理没见过的输入,也有办法追溯上文提到的实体信息。但是,凡事有利就有弊,产生式模型训练难度大,并且很容易犯语法错误(尤其是长句子的生成),而且需要极其庞大的训练数据集。 深度学习技术在两种模型的搭建中都可以使用,最近研究热点已经转向了应用于产生式模型。深度学习中的Sequence to Sequence架构非常适用于生成文字的任务,研究者们希望借助这个架构,在产生式模型领域取得进步。然而,距离我们搭建出一个像样的产生式模型还有很长的路要走,当前工业界的主流还是基于检索的模型。 长对话模型 vs. 短对话模型短对话(Short Conversation)指的是一问一答式的单轮(single turn)对话。举例来说,当机器收到用户的一个提问时,会返回一个合适的回答。对应地,长对话(Long Conversation)指的是你来我往的多轮(multi-turn)对话,例如两个朋友对某个话题交流意见的一段聊天。在这个场景中,需要谈话双方(聊天机器人可能是其中一方)记得双方曾经谈论过什么,这是和短对话的场景的区别之一。现下,机器人客服系统通常是长对话模型。 开放话题模型 vs. 封闭话题模型开放话题(Open Domain)场景下,用户可以说任何内容,不需要是有特定的目的或是意图的询问。人们在Twitter、Reddit等社交网络上的对话形式就是典型的开放话题情景。由于该场景下,可谈论的主题的数量不限,而且需要一些常识作为聊天基础,使得搭建一个这样的聊天机器人变得相对困难。 封闭话题(Closed Domain)场景,又称为目标驱动型(goal-driven),系统致力于解决特定领域的问题,因此可能的询问和回答的数量相对有限。技术客服系统或是购物助手等应用就是封闭话题模型的例子。我们不要求这些系统能够谈论政治,只需要它们能够尽可能有效地解决我们的问题。虽然用户还是可以向这些系统问一些不着边际的问题,但是系统同样可以不着边际地给你回复 ;) 挑战?在搭建聊天机器人的过程中,有许多公认或是还没被注意到的挑战,这些挑战也是当下该研究领域的热门探索方向。 挑战1:结合上下文聊天机器人要产生合理的回答,需要结合语境(linguistic context)和实体信息(physical context)。人们在交谈时,通常会记得双方说了什么、哪些信息被改变了,这就是语境。当下流行的结合语境的方式是将对话用词向量(word2vec)表示出来,但是这种方式在面对长对话场景时具有挑战性。研究者们在 Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models 和 Attention with Intention for a Neural Network Conversation Model 中对长对话场景下的结合上下文挑战做出了探索。此外,诸如日期/时间,地点,用户信息等实体信息,也是需要考虑的。 挑战2:个性化信息一致我们希望聊天机器人在遇到语义上一致的问题时能够给出一致的回答。举例来说,你希望对于“你多大?”和“你几岁了?”这两个问题,机器人能够给出同样的回答。这听起来简单,但是如何将这样相对固定的个性化信息嵌入模型中,却是一个正在研究的难题。当前,许多系统致力于产生语义相关(回答和问题相关)的回答,但却不能产生语义一致的回答,因为通常训练数据来自于许多不同的用户。在 A Persona-Based Neural Conversation Model 一文中,研究者们对于这一挑战做出了探索性的尝试。 挑战3:模型评估标准评估一个聊天机器人模型的好坏,最好的指标是看它能否完成给定的任务,例如,电脑故障助手根据用户的问题,返回的回答解决了一个电脑故障。但是,采用人工评价来衡量一个模型的好坏开销太大了,并且,还要考虑例如开放话题场景下的漫无目的的会话。目前,流行的衡量标准BLEU,最开始是用于评价机器翻译模型的。它是基于文本匹配的统计方式,实际上并不适用于评价聊天机器人模型,因为两个同样合适的应答,它们可能具有完全不一样的表达方式。事实上,已经有研究者在 How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation 一文中提出,目前流行的一切用于聊天机器人评测的标准都不能正确反映系统的水平。 挑战4:回答的意图和多样性产生式模型有这样一个普遍问题:它们倾向于产生类似于“That’s great!”或是“I don’t know”等万金油型的回答。Google的Smart Reply的早期版本几乎对于所有问题,都会回复“I love you”。造成这种现象的部分原因是训练数据的构成(可能很多条数据的回答都是诸如此类的)以及训练模型的算法(使得产生的回答和训练数据集内的回答概率分布相似)。现在一些研究者已经在尝试通过改进训练模型的目标函数使得产生的回答具有多样性。现实生活中,人们会根据不同的提问场景,给出具有特定意图的回答,因此体现出了回答的多样性。然而这一点,对于在不具备特定意图的训练数据集上训练出来的产生式模型,尤其是开放话题场景下,目前是比较难做到的。 聊天机器人实际表现如何?介绍了聊天机器人领域的前沿研究现状,那么聊天机器人实际上表现得如何呢?让我们回过头看一下模型分类。一个开放话题场景的基于检索模型显然是不现实的,因为你不可能把所有的回答都编入“回答集”中。一个开放话题场景的产生式模型应该说是最智能、最符合我们预期的,理论上它能应对任何场景,然而我们距离实现这样一个“智能的聊天机器人”还有很远(虽然有很多研究者正在探索)。 这些问题使得我们不得不先考虑实现封闭话题场景下的聊天机器人,因为此时产生式模型和基于检索的模型都能发挥作用(之前我们说过,当前工业界用得较多的仍是基于检索的模型)。对话越长,上下文信息越重要,问题就变得越复杂。 在一个最近的采访中,现百度首席科学家Andrew Ng说的好:
许多公司推出他们的对话系统,并承诺当他们收集到了足够多的数据,这个系统就能运转良好。这种承诺只有在面对一个特别狭窄的话题领域——如叫一辆Uber的对话才有可能兑现。任何稍微将话题领域扩大一些的尝试(例如销售电子邮件)现在都比较失败。当然了,人们还是可以借助这些不太完善的系统,加入一些主观纠正,达到便利处理事务的目的。 在实际的会话产生系统中,语法错误会让用户体验变差,可能使得公司付出昂贵的代价。这就是为什么当今大多数的系统还是基于检索的模型。如果这些公司能够想办法获得大量的数据,那么产生式模型在一定程度上还是可行的——但是仍有许多其他亟待解决的技术难题,防止系统如Microsoft的Tay所说的走上一条错误的道路。 敬请期待&阅读列表我们将在下篇blog中具体讲述如何用深度学习搭建一个基于检索模型的会话系统。如果你有兴趣深入了解这个领域的前沿研究,以下的这些文章会是一个不错的起点:
点击下方的阅读原文,可以查看文中蓝字部分的超链接文章哦 :) 上一篇:没下限?WP Engine 被 WordPress .org 禁止访问 下一篇:【精华回顾】腾讯云数据库实现全链路自主创新升级,让客户“开着飞机换引擎” |
 微信公众平台持续治理“假冒仿冒”行为16129 人气#新媒体课堂
微信公众平台持续治理“假冒仿冒”行为16129 人气#新媒体课堂 公众号案例 | 鲲鹏产业源头创新中心微信公28355 人气#新媒体课堂
公众号案例 | 鲲鹏产业源头创新中心微信公28355 人气#新媒体课堂 萌芽加速 adminCDN 上线,由文派开源提供的17974 人气#站长圈
萌芽加速 adminCDN 上线,由文派开源提供的17974 人气#站长圈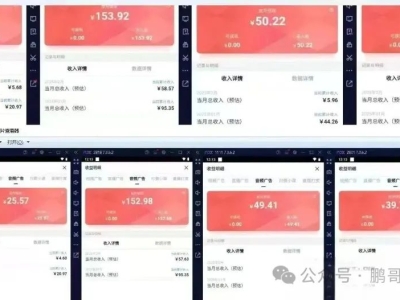 搜狐音频挂机项目揭秘:月入八千+的红利期操28845 人气#站长资讯
搜狐音频挂机项目揭秘:月入八千+的红利期操28845 人气#站长资讯
 /1
/1 
 AI智能体
AI智能体









