PostgreSQL通过数据冗余和日志同步实现一主多读,并允许备机在主机不可用后,替换主机继续对外提供服务,保证系统的可用性。 而在TDSQL-C for PG 的计算-存储分离架构里,数据库实例共享同一份数据,一主多读的设计与传统数据库相比也有很大差异。本文将由腾讯云数据库专家工程师邹立贤为大家带来TDSQL-C PG版的主从架构详解。 TDSQL-C PG版整体架构为什么我们要做TDSQL-C这款产品?在传统数据库上,数据库的使用是存在一些问题,主要分为以下四个: 第一是资源利用率低,计算和存储在一台机器上,CPU和磁盘使用不均衡,例如CPU用满,但磁盘很空闲或者CPU很空闲但磁盘又满了,这样就会导致资源利用率低。 第二是扩展能力不足,在单机上可能不能满足一些用户要求,无法扩展。 第三是资源规划难,例如用户使用数据库,一开始无法预估这个数据库需要多少次磁盘空间。 第四是备份比较困难,因为每一个实例数据是私有的,所以每个实例都需要单独进行备份。 TDSQL-C的解决思路,第一个问题是计算存储分离,计算资源可以弹性调度。例如一开始用户购买的是一个4核8G的节点,一段时间以后业务增加可能会发现这个规格无法满足他的业务要求,那么他可以购买一个更大规格实例,比如16核32G,这个相当于做计算资源的升配,类似的我们也可以支持降配。第二个问题是日志下沉以及异步回放,TDSQL-C的日志是通过网络,从计算层下放到存储层。第三个问题是共享分布式存储,我们TDSQL-C地域的所有实例,在底下是共享一个分布式存储,可以动态向一个实例里添加资源。最后一个问题解决思路是后台持续备份,我们的后台有定期备份任务,将日志和数据备份到对象存储上面。 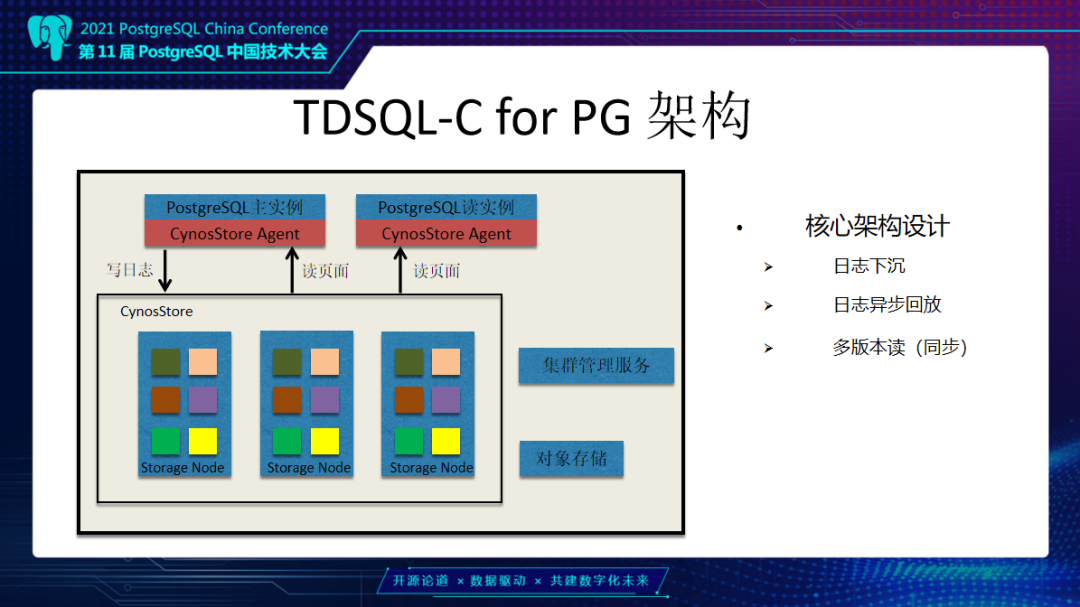 这张图是TDSQL-C PG版整体架构。最上面是PG实例,包括主实例和读实例,主的负责读写,只读是负责数据读取。在PG下有一个叫CynosStore Agent组件,它主要负责和存储层进行通信,包括主的写日志、读页面,从的是读页面。再向下是存储服务或叫CynosStore,采用的是Raft结构,一主两从。右边是集群管理服务,是对CynosStore里存储节点进行管理,包括故障迁移等,例如当一个节点发生故障后,将服务迁移到其它节点。 另外,当需要扩展资源时,也是由这个集群管理服务来实现。下面是对象存储,我们会定期在对象存储上备份日志和数据。这里涉及几个核心架构:一个是日志下沉,计算节点产生的日志是通过网络,下沉到存储层。存储层是通过异步方式来回放日志,最终回放到页面上去。另外是我们会提供一个多版本读的能力,PG上层可能会有多个后台会话同时去读取数据,每个会话开始的时间不一样,可能会读到不同的版本。 下面介绍TDSQL-C日志下沉、异步回放。这里涉及几个概念: 第一个是数据原子修改,我们叫MTR。数据库当中有很多情况是一次操作需要同时修改多个数据页面,例如btree索引分裂,或是一条Update语句,它会涉及两条元组,这两条元组可能分布在不同的页面上,这些都需要保证是原子操作。第二是CPL概念,我们MTR里修改了多条数据页面,最后一个产生日志的点我们叫它CPL;另外一个是VDL,VDL是存储层所有连续CPL里的最大值。随着数据库在运行中,这个VDL是在不断地向前推进。同时我们的TDSQLC-PG的读操作需要拿到一个读点,这个读点就是一个个的VDL。 第二个是日志异步写入。日志异步写入是由我们PG进程来生成日志,写到我们的日志Buffer,日志Buffer是PG进程和我们CynosStore Agent进程之间共享的。日志写到这个Buffer以后,由Agent进程把它们异步的发送到存储节点。存储节点把收到的这些日志挂到日志链上,再异步合并到数据页面上去,整个过程都是异步的。 第三个是日志并行插入。上层PG实例可以有多个后台会话同时去写日志,这里采用一个并行的方式,可以加快日志的拷贝。 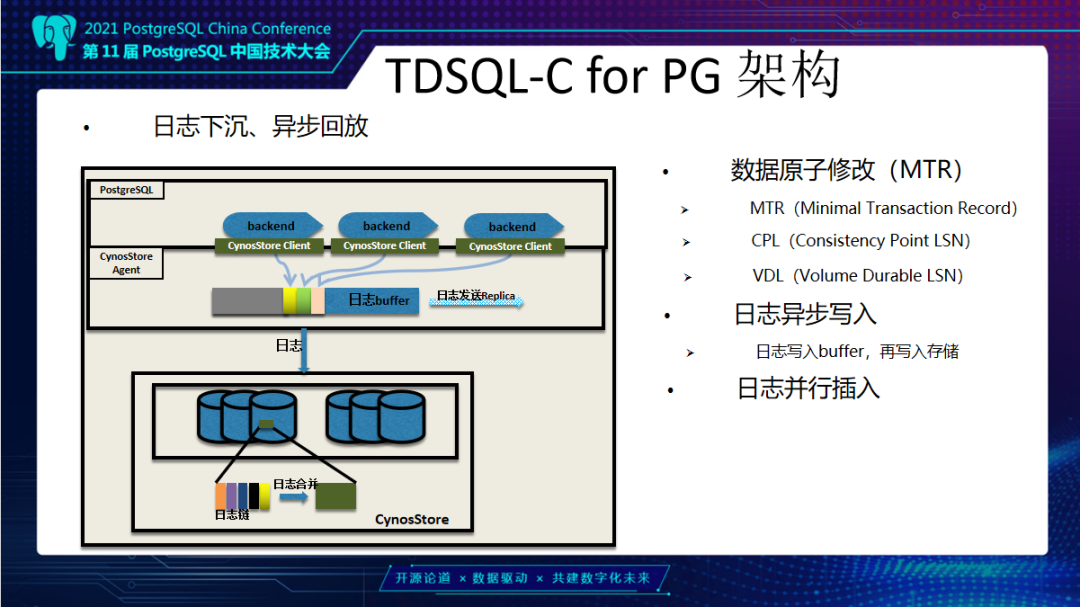 接下来看一下,TDSQL-C PG版的主机优化: 第一点是不必依赖于传统PG的CheckPoint机制。大家都知道传统PG有个CheckPoint,定期把数据库中日志和对应修改的数据页都刷到本地磁盘上,这是一个比较耗时的操作。那在我们的系统里边由于是存算分离,日志是异步通过存储节点来回放,所以就没有了CheckPoint刷藏页的机制。 第二点是不需要在日志中记录全页。PG上有一个概念,叫Full Page Write,在每个CheckPoint之后,对每个数据页面的第一次修改,需要把这一个完整的数据页面内容写入到日志当中。这是为了防止断电情况下可能产生数据页面的半页问题,而在我们这种架构下不需要这个,可以减少很多日志。 第三点是快速启动系统。在启动时不需要恢复XLog,可以很快的将数据库启动起来提供服务。传统PG它是先需要恢复大量XLog以后,达到一致点才可以对外提供服务。 最后一个是日志合并压缩。这个是在对一个数据页面做修改时,往往需要修改这个页面多个不同偏移,比如说从第0个偏移改8个字节,然后需要从第30个字节开始改4个字节,会涉及到多个修改。我们把同一页面多个修改抽象出来一个共享日志头来减少日志大小,进一步减少IO。  TDSQL-C PG版主从结构接下来介绍TDSQL-C PG版的主从架构。传统数据库PG主备模式是先把日志写到本地磁盘,再由主机的 WalSender 进程把XLog读取出来通过网络发送到备机,备机有个 WalReceiver 进程接收到这部分日志写到本地磁盘,再由PG恢复进程Startup读出来,把XLog对应的修改应用到数据页面上去。但是它有几个缺点,第一个是在创建备机时,需要拷贝主机日志和数据这部分内容,这部分内容拷贝需要一定的时间,当实例比较大时这个代价就更大了,第二点是备机和主机的数据不是共享的,备机也需要耗费存储资源,另外,在备机切换成主机和启动过程中,它都是需要去恢复XLog,达到一致性状态之后才能对外提供服务,这可能会导致启动比较慢。 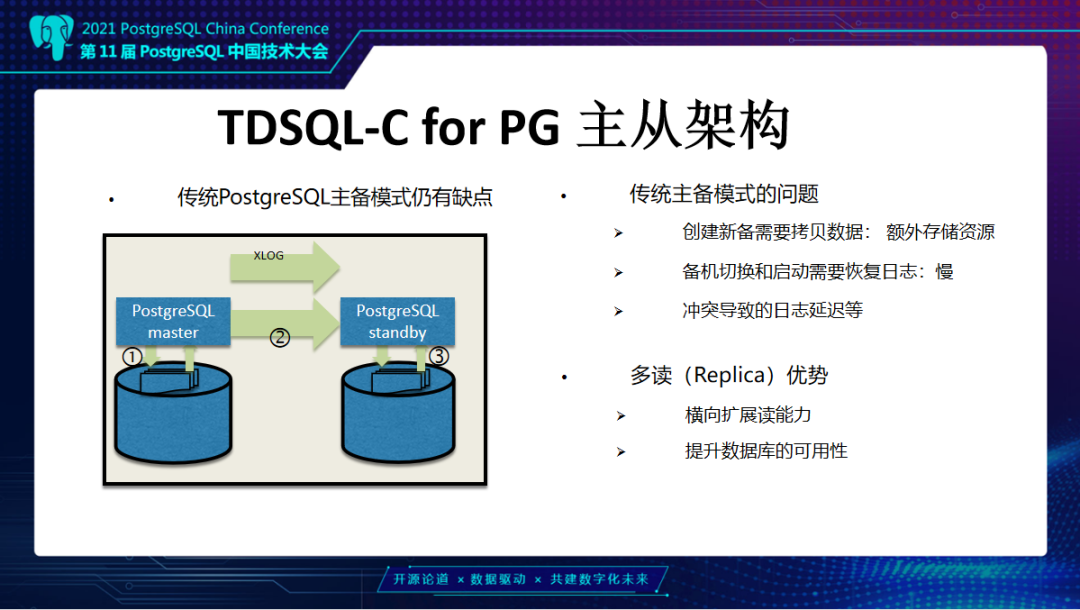 而TDSQL-C采用的一主多读模式有以下两种优势:第一个是由于我们搭建从机速度很快,所以横向扩展读能力会比传统PG好很多,我们搭建从机不需要考虑数据,因为我们的数据是共享的。第二个是由于我们横向扩展能力强,所以从提升主时也不需要来恢复日志,在提升数据库可用性这方面比传统PG好很多。 接下来介绍主从架构里边多个节点并恢复日志的实现。这张图里面是一主三从结构,可以看到主从之间发送日志是在我们CynosStore Agent这个组件里进行。从机是由CynosStore Agent组件来接收日志。接收到日志会把它先写到本地磁盘,PG进程再读上来写到共享hash表里生成日志链,这个日志链的Key就是Block ID。 这些日志大致分为两类:第一类是运行时一些信息,包括事务列表,还有锁,还有一些运行时快照等信息。另外一类是对数据页修改产生的日志,包括Heap页面、索引页面这些。挂完链以后,这些链上的日志是由PG的后台进程读取,然后将日志对应的修改应用到页面上。和PG不一样的地方在于,当我们要应用的日志对应的数据页面不在内存中时,我们会跳过这条日志的恢复,也就是不需要从存储上把数据页读出来后再恢复到内存中。这一点是和传统PG不一样的地方。 TDSQL-C PG版主从机优化接下来介绍TDSQL-C PG从机优化,传统PG从机由Startup进程去读XLog,可以看到它不管页面是不是在Buffer中,它都是需要去存储中把对应数据页面读出来,把XLog应用后再恢复下一条。因为它的数据不是共享的而是私有的,如果不恢复对应日志就会丢失数据。 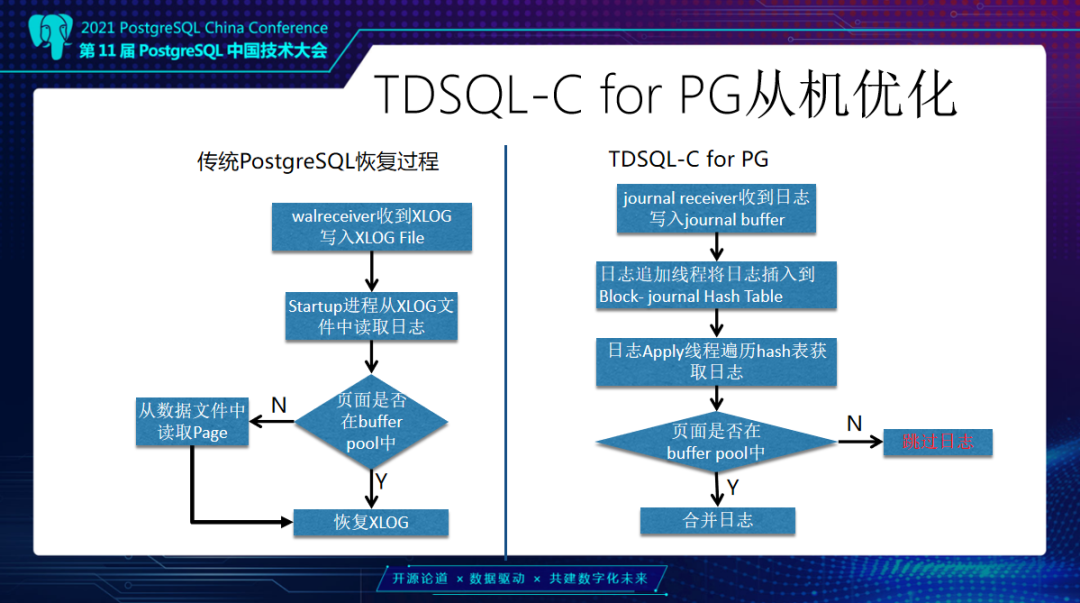 我们和它的区别一是我们有多个应用日志进程来应用日志,加快应用速度。二是当这个页面不在Buffer的时候,我们可以跳过这部分日志,就不需要去读上来再恢复。 从机并行合并日志,这个图里画的是ABCD有这么四个数据块,每个块上面是括号里的值表示的是当前数据块日志应用到的位置,11、17、15、9,它们表示的就是当前数据块应用位置。假设现在又来了12、18、16、19对应日志,那就会有多个Merge进程来对这些没有相关性的数据块做并行的恢复。例如第一个Merge进程会对A和B这两个数据块做恢复,另外一个Merge进程可以对C这个数据块做恢复,它们之间是并行的。每恢复完这样一些数据块后,我们的VDL就可以向前推进,比如说从17到19,后面恢复更多的日志后,可以不断的向前推进。 接下来介绍从机优化,是针对DROP表和DROP数据库优化。在数据库PG中,当主机上DROP一个表或DROP一个DB时,从机需要做这么几件事: 第一是要删除,把这个表或者这个数据库在系统表当中的元数据删除,像pg_class、pg_attribute 这些系统表当中的元数据,要先给它删掉。 第二是需要遍历一下Shared Buffer,这些表或数据库可能在从机上去访问过,它可能在Buffer里留下了一些页面,我们需要把这些页面找到,让它失效掉。 第三是发送失效消息,就是这个表或数据库的失效消息。通过失效消息队列,通知其它进程,然后是删除外存文件。  这里的第二步是失效Shared Buffer,这个操作比较耗时。按照默认PG的一个Buffer是8K来算,那么1G的Shared Buffer就会有13万个左右的Buffer,64G大概会有800多万个Buffer。主的删除一张表,在从机这边可能要遍历800万次Buffer,找到这些要失效的页面,去淘汰。当一次性删除的表比较多的时候,比如删除一个schema,这个schema下面可能有几十张表时,那么这个遍历次数就更多了。 我们这里做了一个优化,就是将它的第二步也就是遍历Buffer,失效Buffer的操作,把它单独拿出来做为一个进程来做这件事。这个地方我们叫Log Process。它和Startup进程之间是通过共享队列方式来通信。当需要失效 Buffer的时候,Startup进程会把对应的DB ID或表ID放到队列中,然后通知Log Process,Log Process收到通知后会从队列里面取到这个DBID或表ID,再去遍历Buffer,将对应Buffer失效掉。 另外一个优化也是和DROP 表相关的,PG从机在恢复一张表时,会把这个表的信息保存在内存中的一个单向链表中,当恢复到这个表的删除操作时,从机再从单向链表中把这个表找到并移除掉,也就是这个表第一次创建时,从机会把它保存到一个链表中,当主机删除的时候,从机会把这个表信息从单向链表中找出来,把它进行删除。 当我们表比较多的时候,比如说有几千、几万张表时,单向链表长度也是几千、几万。当要删除这个表时,要从几千、几万个元素的单向链表中找到要删除的节点的前向节点,把它指向要删除这个节点的后向节点。这里,当删除多个表时,单向链表查找是一个比较耗时的操作。 这里修改比较简单,就是把单向链表改为双向链表。删除时,把要删除这个节点的前向节点指向它的后向节点,它的后向节点指向它的前向节点,就可以达到删除的目的。有了这个优化,加上异步失效Buffer的优化,在有一定压力情况下,日志堆积可以从之前的100GB降低到几MB、几十MB这个级别,基本没有日志堆积了。 接下来是介绍一下传统备机和TDSQL-C PG版的启动。传统PG启动的时候恢复到一致性的点才能对外提供服务。当前画的这个图里比如说最小恢复点是50,而恢复当中又来了一个CheckPoint,比如说CheckPoint里记录的是1000,那么它在下一次启动时需要恢复到1000这个点才能对外提供服务。 在TDSQL-C PG版里,从机启动时,是需要拿到一个持久化VDL就可以获得存储一致性状态,而这个VDL是可以从主机传过来的日志当中计算出来。这个速度比PG快很多。第二个是可以快速搭建从机,因为不需要复制全量数据。 最后一个优化解决的问题是避免PG在发生主从切换时可能会出现双写的问题,导致日志“分叉”。例如一个一主一从的PG实例,当发生切主时,由于某些原因旧主并没有死掉,可能有些应用还是连接在旧主上面,但是另外一些应用连到新主上面,会导致两边数据不一致,需要人工干预才能把数据库恢复到一致状态。 TDSQL-C PG版采用的是HA Fencing机制。当每一个主实例在启动开始写日志之前,会通过网络去我们的Meta服务上面获取一个Fencing值,这个Fencing值是全局唯一递增的。计算层每次往存储层写日志时都会带着这个值。 当发生主从切换,切到一个新主上时,新主又会去Meta服务上拿到一个新的Fencing值,例如旧主拿的是100,旧主存储节点通讯时都会用100;后面从机切为新主,新主会拿到101,然后它就用101和我们的存储节点通信。这时假设旧主还通过网络,以100往存储上写日志,存储就会拒绝这个日志的写入,从而达到了避免日志分叉的目的。 未来展望对未来的一些探索,我们可能会采用一些新硬件,包括RDMA。另外,现在是一种多从的架构,未来会尝试做多主架构、Serverless无服务化这些来降低计算成本,可能还会做一些兼容性方面的工作,例如Oracle兼容性这些。以上我今天的分享,谢谢大家。 ﹀ ﹀ ﹀  腾讯云在PostgreSQL领域的‘‘再次突破’’  硬核干货 | 轻松驾驭EB级千万QPS集群,TDSQL元数据管控与集群调度的演进之路 ↓↓点击阅读原文,了解更多优惠 上一篇:微信表情符号写入判决书,还能用表情斗图愉快聊天么? 下一篇:Sqlmap-tamper的介绍及总结 |
 微信公众平台持续治理“假冒仿冒”行为16130 人气#新媒体课堂
微信公众平台持续治理“假冒仿冒”行为16130 人气#新媒体课堂 公众号案例 | 鲲鹏产业源头创新中心微信公28360 人气#新媒体课堂
公众号案例 | 鲲鹏产业源头创新中心微信公28360 人气#新媒体课堂 萌芽加速 adminCDN 上线,由文派开源提供的17978 人气#站长圈
萌芽加速 adminCDN 上线,由文派开源提供的17978 人气#站长圈 搜狐音频挂机项目揭秘:月入八千+的红利期操28851 人气#站长资讯
搜狐音频挂机项目揭秘:月入八千+的红利期操28851 人气#站长资讯
 /1
/1 
 AI智能体
AI智能体









