阿里达摩院上线文本生成视频大模型:仅支持英文输入,已开放试玩 |
我要说一句
收起回复
| |
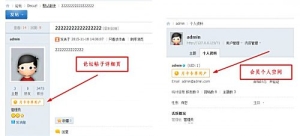 月卡多卡版 4.1(yueka)641 人气#Discuz!插件模板
月卡多卡版 4.1(yueka)641 人气#Discuz!插件模板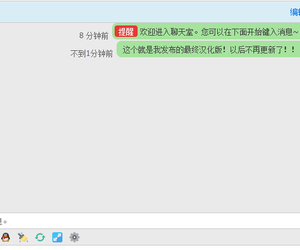 与dz-x.net同款首页聊天室 最终汉化版!1921 人气#Discuz!插件模板
与dz-x.net同款首页聊天室 最终汉化版!1921 人气#Discuz!插件模板 平安批量发贴 商业版1.5.4(boan_batchpost)1085 人气#Discuz!插件模板
平安批量发贴 商业版1.5.4(boan_batchpost)1085 人气#Discuz!插件模板 多米网址导航 自适应版(domi_hao)101 人气#Discuz!插件模板
多米网址导航 自适应版(domi_hao)101 人气#Discuz!插件模板 美化附件美化助手 1.5(tshuz_attachpro)101 人气#Discuz!插件模板
美化附件美化助手 1.5(tshuz_attachpro)101 人气#Discuz!插件模板 礼物商城/送礼中心 正式版1.0(viewui_gift)101 人气#Discuz!插件模板
礼物商城/送礼中心 正式版1.0(viewui_gift)101 人气#Discuz!插件模板





 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜
